Sobre las encuestas: imposible saber
Actualizado:
Queremos ser enfáticos en sostener que creemos que no es posible realizar un pronóstico certero para la elección presidencial de 2021. Como organización, hemos investigado la interacción entre las encuestas y los escenarios bajo los cuales pueden ser utilizadas para anticipar resultados de elecciones y hemos concluido que bajo el contexto político y social actual es extremadamente difícil.
Imposible saber: sistema inestable, información contradictoria
Por: Kenneth Bunker
Primero, es importante señalar que este artículo se publica en medio del debate que se está dando en círculos académicos y en la esfera pública sobre la capacidad predictiva de encuestas. Tresquintos nació para monitorear encuestas de opinión pública y no para ser complaciente con ellas. Por lo mismo, nos mantendremos en ese rol, archivando y poniendo a la disposición de nuestros lectores toda la información que creemos que pueda ser relevante.
Segundo, nos sumamos al punto de fondo que tocan dos columnas de opinión recientes sobre lo que está ocurriendo en el mundo de las encuestas. La primera, es la columna de Alejandra Matus en Tercera Dosis: El lugar donde las encuestas pierden la seriedad. Si bien la investigación viene de una línea periodística, descriptiva, y en ciertos puntos se construye en base a ejemplos puntuales, creemos que toca temas cruciales.
Lo relevante de la columna de Matus es que alumbra factores claves que pueden estar dañando la capacidad predictiva de las encuestas. No vamos a entrar en detalles aquí, porque los argumentos están expuestos de forma clara en su columna, pero tienen que ver con todo lo que está bajo el capot, desde las tasas de respuestas hasta el proceso de depuración, y desde el trabajo de campo de un encuestador hasta el rol del supervisor.
La segunda columna es la de Noam Titelman, también publicada en Tercera Dosis: Seis razones por las cuales las encuestas están fallando en Chile y el mundo. Si bien es una columna de corte general, creemos que tiene mérito. Cada uno de los seis puntos que se mencionan son cruciales, y creemos que pueden ayudar al público general a entender por qué se equivocan las encuestas.
Para personas que buscan un soporte intelectual para sostener sus argumentos “en contra” de las encuestas, es una columna perfecta. Resume muy bien los argumentos de cómo las encuestas se pueden equivocar, entrelazándolo con el rol de los medios, y cubriendo la problemática que significa para la democracia en general. El autor toca temas que rara vez se discuten en el foro público local, y por lo mismo es de gran importancia.
En fin, ambas columnas tienen mérito y la intención aquí no es repetir lo que allí se ha hecho. Aquí, en cambio, se busca complementar el debate con más información sobre lo que sabemos de las encuestas en los últimos años de una perspectiva comparada. La idea es también generar un puente entre ambas contribuciones, unificando lo especifico con lo general, y la evidencia que conocemos de la experiencia chilena con que se ha observado en otras partes del mundo.
Es importante partir precisamente por lo último: ¿se equivocan las encuestas? Normalmente se da a entender que sí. Comúnmente se cita a Brexit y a la elección de Trump como ejemplos. Pero es sabido que ninguna de esas elecciones son buenos ejemplos. En ambos casos, las encuestas estuvieron dentro, o muy cerca, de los márgenes de error reportados. En el caso de Estados Unidos, el problema fue la proyección de resultados combinados por Estados.
Para no entrar en detalles, y alargar este texto innecesariamente, el punto es que las encuestas no están peor que antes. Hay literatura que lo demuestra, partiendo por el estudio de Jennings y Wlezien en Nature (ver aquí). Revisando 30 mil encuestas de 351 elecciones generales en 45 países entre 1942 y 2017 encuentran que, contrario a la sabiduría convencional, el desempeño reciente de las encuestas no es peor que la histórica. Keeter lo reafirma.
Un punto relevante del artículo de Jennings y Wlezien es que el error de las encuestas varía según contexto político. Esto no puede ser dejado fuera del análisis. Por ejemplo, no da lo mismo si la encuesta se hace dentro de un contexto democrático estable o en medio de un periodo de crisis. Evidentemente, solo por intuición, pareciera obvio que las encuestas responderían de mejor manera en el primer contexto. Volveremos a esta idea más abajo.
Antes, es importante recalcar que el punto de la discordia (al menos aquí) es sobre la “capacidad predictiva de las encuestas”; no si son moralmente aptas. La idea es identificar los factores que hacen a una encuesta más certera que otra. En esa línea, aunque suene crudo, el método se vuelve irrelevante cuando la encuesta logra acertar a los resultados. La premisa, desde este ángulo, es que al final del día, lo que importa es la capacidad predictiva de una encuesta.
Ese tema ha sido largamente discutido dentro del mundo académico de los pronósticos electorales (electoral forecasting): cómo anticipar resultados de elecciones. Y allí hay diferentes métodos. Uno de varios se basa en la agregación de encuestas. Su utilidad es que es simple y no requiere muchas premisas. Obviamente corre el riesgo de terminar siendo un modelo GIGO. Lo que sucede, sin embargo, es que en general tienden a ser relativamente certeras
Hay muchos ejemplos de este tipo de estudio en el mundo, pero un estudio que es familiar para nosotros es A two-stage model to forecast elections in new democracies. Ese estudio, hecho con datos de encuestas de 10 países de América Latina (para ir moviéndonos hacia el caso chileno), muestra que es posible construir modelos predictivos que anticipan resultados de elecciones dentro de márgenes aceptables.
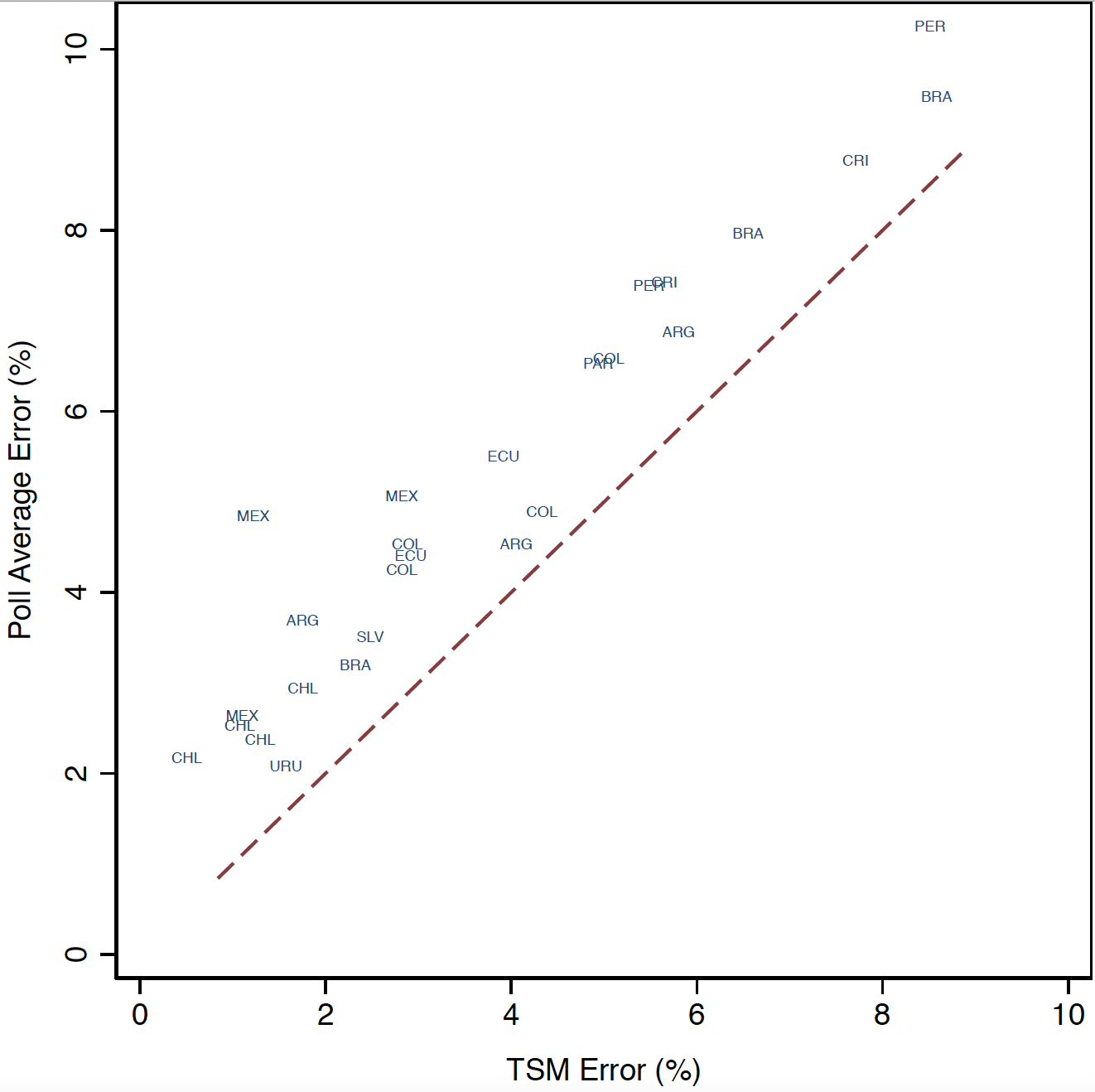
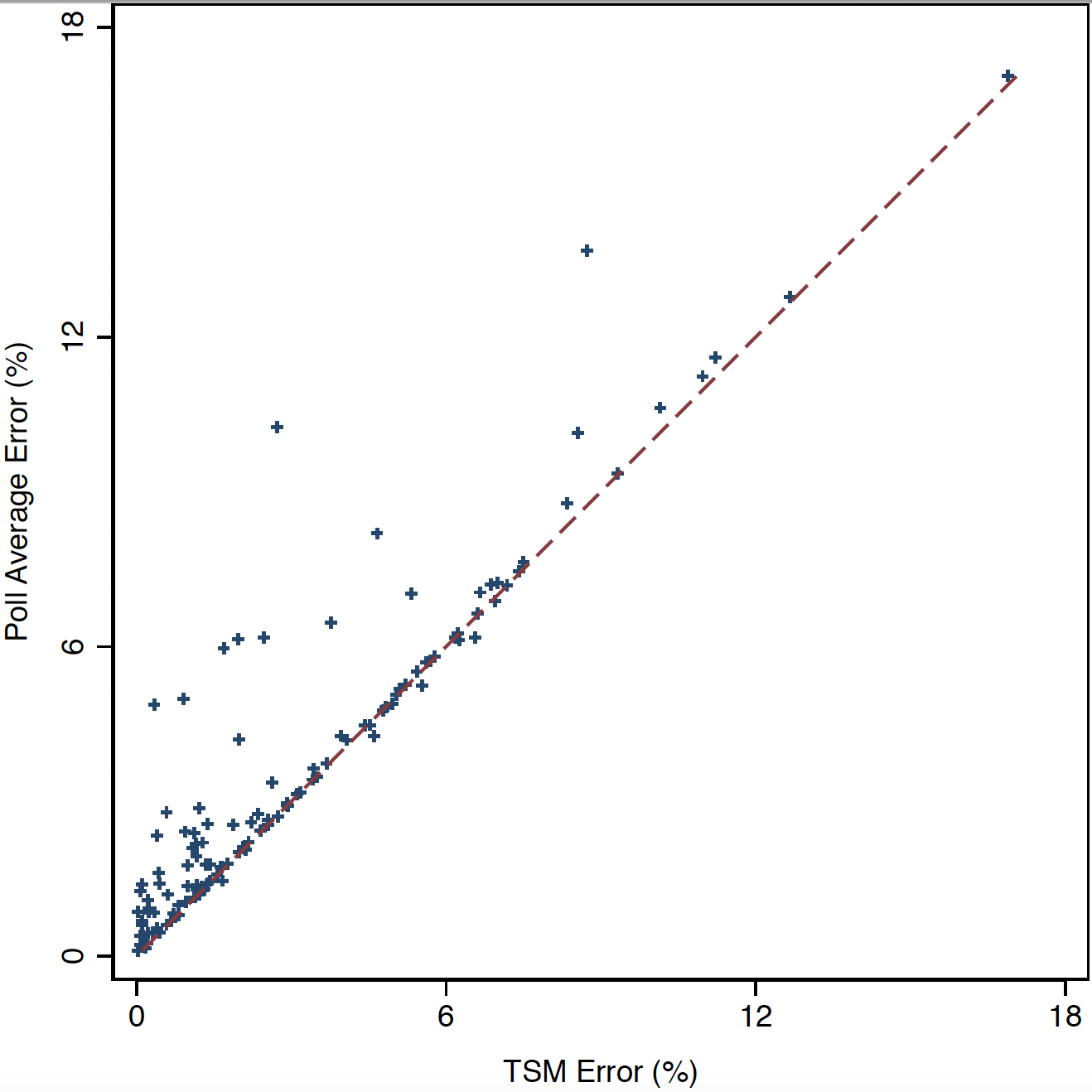
Los gráficos de abajo muestran la comparación entre el error de las encuestas y el error del modelo predictivo presentado en ese artículo. El gráfico de la izquierda muestra el error absoluto promedio por elección, y el gráfico de la derecha muestra lo mismo pero desagregado a nivel de candidatos presidenciales. Si el error fuera igual entre encuestas y el modelo de agregación, los errores caerían en seguidilla sobre la línea roja de 45 grados.
Pero lo que muestran los gráficos es que en la gran mayoría de los casos el modelo es superior a las encuestas (produce un error más bajo). A pesar de que el error puede ser alto en algunos casos, rara vez el modelo produce un error más alto que el de las encuestas. Esto va al punto de que, aunque la información que entre sea mala (la cual, como ya sabemos, no necesariamente es el caso), la información que sale puede ser útil.
Pasemos a revisar cómo se relaciona todo esto con el caso chileno, y las razones de por qué nosotros no vamos a realizar un pronóstico en 2021. Para empezar, es importante subrayar que no repetiremos lo que ya se ha dicho en otros lugares, de forma clara y concisa. Por lo mismo, quizás a algunos, quienes no están siguiendo el debate más coyuntural, todo esto les parecerá abstracto. A ellos les recomendamos revisar los enlaces en detalle.
Comencemos. Se dice, y se repite, una y otra vez, que en Chile las encuestas son malas. Que no le apuntan. Que no sirven. Pero, ¿es cierto? ¿Dónde están los datos? ¿Dónde están las referencias a las encuestas? ¿Dónde están los estudios con los números, mostrando la magnitud de los aciertos y errores? Si solo repetimos que las encuestas de 2017 fallaron porque no le apuntaron ni a Piñera ni a Sánchez, no aprenderemos nada.
Pues bien, Tresquintos tiene algo de experiencia en ese análisis, habiendo seguido elecciones en vivo desde al menos 2010. Y una cosa que hemos aprendido es que las encuestas se equivocan, pero también le apuntan. No todo es color de hormiga. Lamentablemente, sin embargo, en la mayoría de las notas publicadas en los medios esto no se menciona. Simplemente se comienza de la base que las encuestas no sirven. Esto es problemático para el debate en general.
Lo cierto es que en Chile hay estudios del comportamiento de las encuestas. Una investigación temprana, Pronósticos Electorales y Seguimiento de Opinión Publica en Latino América: Una aplicación a Chile, cubre las elecciones de 2005, 2009 y 2013. Lo que muestra es que es más fácil predecir elecciones de lo que se piensa. Para esas elecciones fue relativamente sencillo construir modelos predictivos para apuntarle a los resultados (expost en el caso de 2005 y 2009).
A todas luces, la “crisis” de las encuestas en Chile comienza en 2017. No entraremos en profundidad en las razones bajo el capó de las encuestas locales, ni tampoco en la teoría general de por qué las encuestas se equivocan (porque, otra vez, eso está desarrollado en otra parte). Pero sí es importante notar que hasta 2013 las encuestas le apuntaban relativamente bien a los resultados (dentro de ciertos márgenes).
Como es sabido, el problema de 2017 fue, principalmente, la sobreestimación del resultado para Piñera y la subestimación del resultado para Sánchez. No hay que minimizar eso. Pero, para el resto de los candidatos (los otros 6), las encuestas estuvieron relativamente certeras, dentro de sus márgenes. Esto vuelve al punto de que cuando las encuestas aciertan, se suele barrer bajo la alfombra. Después de todo, ¿quién tiene interés en defender a las encuestadoras?
El hecho es relevante, porque lo que nos dice es que no es todo error; el error es especifico y localizado. Si fuera solo el método el que estuviera fallando uno esperaría un error más bien uniforme, distribuido normalmente, y para todos los candidatos (quizás con mayor error para los candidatos con más preferencias). Pero no es el caso, hay aciertos. En 2017 también. ¿Cuál es la explicación?
Una hipótesis, presentada aquí, y con raíces en Jennings y Wlezian, y otro estudio que mencionaremos más abajo, tiene que ver con el contexto político. No se puede ignorar las condiciones políticas bajo las cuales se hacen encuestas. Para ser estridente, en 2017 se movieron capas tectónicas. Cambió el sistema electoral, cambió el sistema de partidos. Murió el sistema de dos coaliciones y se asomó otro, de tres o cuatro coaliciones, como se sostiene aquí. Eso importa.
El punto de fondo es: ¿cómo van a apuntarle las encuestas si todo está en movimiento? Por ejemplo, si quieres sacarle una foto a una persona y esa persona se mueve, la foto sale borrosa. Mientras más se mueve la persona, más borrosa sale la foto. Esa es la teoría. En parte, las encuestas fallan cuando las cosas se mueven. Particularmente cuando no hay equilibrio ni en el sistema electoral, ni en el sistema de partidos, ni en el sistema democrático.
Y ese es el caso de Chile hoy, no hay estabilidad (equilibrio) en ninguna de esas tres áreas. Hay más bien una sensación de que, por un tiempo al menos, todo seguirá en movimiento, con incertidumbre. Se ve incluso en el ciclo electoral. Candidatos cambian sus estrategias, suben en las encuestas, cambian sus programas, bajan en las encuestas, se entabla una acusación constitucional, suben en las encuestas, se pone en duda el cuarto retiro, bajan en las encuestas.
Evidencia de esta teoría se puede encontrar en lo que ocurrió en el plebiscito de 2020. Pues, aunque muchos repiten que las encuestas se equivocaron, no dicen que sí hubo varias a las que les fue bien (así como también a los agregadores de encuestas, como Tresquintos). Pero hay un detalle muy importante, crucial, critico, que pasó en esa elección que sin eso no habría premisa para sostener y desarrollar la tesis del movimiento.
Lo inusual de 2020 fue que las encuestas le apuntaron a la primera pregunta, pero no a la segunda. Es decir, estuvieron cerca del 78% del “Apruebo”, pero lejos del 79% de la “Convención Constitucional 100% elegida”. Eso es algo extremadamente raro. ¿Cómo es posible que ocurra aquello si estaban ocupando los mismos métodos, con las mismas personas, en los mismos trabajos de campo? Sin hacerse cargo de esto, no se puede criticar a las encuestas.
Por eso es extremadamente útil mirar la diferencia entre lo que dijeron las encuestas para cada una de las preguntas y los resultados. Y eso es precisamente lo que hace el artículo Forecasting Two-Horse races: accuracy and precision, a ser publicado prontamente en la Revista Latinoamericana de Opinión Pública (RLOP), en una edición especial de pronósticos electorales coordinada por los académicos Michael Lewis-Beck, Mariano Torcal y Ryan Carlin.
El artículo sugiere que no se puede explicar la diferencia sin considerar el contexto político. Las encuestas acertaron en la primera pregunta no solo porque era más fácil de entender, sino que también porque el electorado chileno estaba decidido previamente. No hubo grandes variaciones en las preferencias durante el periodo de la campaña, porque no había grandes diferencias en la ciudadanía antes del acuerdo del 15 de noviembre.
Comparativamente, la segunda pregunta no solo era más difícil de entender, sino que tampoco tenía una noción predeterminada. Por ejemplo, basado en evidencia anecdótica, muchas personas confundían el término “mixto” con “paridad”. Definir si uno quiere un cambio de Constitución es relativamente fácil en comparación a definir si uno quiere tal o cual mecanismo electoral. La conclusión es que esas preferencias fueron evolutivas, consolidándose en las últimas semanas.
Lo que queda en limpio es que la estabilidad de las preferencias para la primera pregunta no existió para la segunda. Si hubo algo de caos en el periodo que rodeó la elección, se traspasó a la segunda pregunta y no a la primera. En el estudio mencionado arriba esta idea se desarrolla mirando la tendencia a través del tiempo, y observando la interacción de modelos de votante probable (que, notablemente, estuvieron mejor para la segunda pregunta que para la primera).
Aun así, Mori, CIIR, y Activa tuvieron buenos pronósticos para la primera pregunta y Activa estuvo muy cerca de apuntarle a la segunda pregunta. Esto solo sirve para consolidar la idea que generalizar que las encuestas se equivocan es tan problemático como erróneo. En cualquier caso, las sospechas no están fundadas en humo. Es el ejemplo de las encuestadoras argentinas StatKnows y Numen, que fueron literalmente GO.
Ahora, la hipótesis del movimiento cobra aun más sentido cuando se observa la elección de constituyentes, para la cuál no hubo muchas encuestas, pero sí sorpresas. Todos los que hicieron pronósticos sobre esa elección se equivocaron. Nadie le apuntó. En Tresquintos transparentamos los métodos que usamos para hacer las simulaciones, y tampoco le apuntamos. Fue una sorpresa para absolutamente toda la clase política, los expertos y el país. Nadie lo vio venir.
Esa elección se conecta con la tesis del movimiento porque describe elocuentemente el hecho de que hay un electorado fluido que se mueve en las sombras. Antes de la elección de constituyentes se pensaba (erradamente) que las preferencias eran relativamente estables, incluso a la luz del estallido social. Pero cuando se cambió la oferta por medio del sistema electoral (i.e., paridad, pueblos originarios y listas de independientes), cambió la demanda.
El movimiento de esa capa tectónica, si bien no está vinculada de forma directa con lo que pasa en las encuestas (ni menos los problemas que pueden ser inducidos por sus métodos), sí funciona como un eslabón para entender cómo se transfieren votos bajo el radar. Eso lleva a pensar en un segundo elemento, también discutido en el artículo de RLOP mencionado arriba: la veda de encuestas electorales en los últimos 15 días antes de las elecciones.
Ahora, para contextualizar esta idea, y dar algunos ejemplos, avancemos a la tercera elección del ciclo (después del plebiscito de octubre 2020, y la mega-elección de mayo/junio 2021): la elección primaria de julio de 2021, en que ganaron, para muchos inesperadamente, Sebastián Sichel y Gabriel Boric. Esta elección, como todas las otras, también fue objeto de sondeos de opinión pública, y también tuvo una veda de 15 días.
Vamos primero al nivel de asertividad de las encuestas. Muchos repiten que la última encuesta antes de la veda mostraba a Sichel último y de pronto apareció primero (entre ellos el propio candidato lo sugiere). Pero como muestra el registro de encuestas de Tresquintos, esto no es necesariamente cierto. Sin contar ni la Cadem (del 15 de julio) ni la Black and White (del 11 de julio), sí había evidencia de la fortaleza de Sichel.
El 26 de junio se mostró un empate técnico entre Lavín y Sichel en la pregunta cerrada y una ventaja de Sichel en la versión de voto probable (29% vs. 26% a favor del ganador). La encuesta de Data Influye del 28 de junio también mostró un empate técnico. De hecho, en todas las encuestas que logramos recopilar, Sichel y Lavín siempre lideraron la carrera. Al menos desde el 20 de mayo en adelante, las encuestas mostraron a uno u otro como ganador.
¿Se equivocaron las encuestas en la primaria de la derecha? Es discutible. Al menos sabemos que daban a ganador a Lavín o a Sichel. Sichel sí estuvo en la pole position al menos dos veces antes de la elección y siempre fue el runner-up cuando no estuvo arriba. Y si aumentó inesperadamente, puede ser por lo que pasó los últimos 15 días, como buscan sugerir Cadem y B&W (suponiendo que se hicieron en las fechas declaradas y no se editaron expost).
En la vereda de al frente, en Apruebo Dignidad, también se dice que las encuestas se equivocaron. Y aquí sí parece ser el caso, pues lo que muestran las tendencias es que Jadue siempre lideró la carrera y por un margen significativo. Salvo la Cadem del 15 de julio (mencionada arriba), todas dieron como ganador a Jadue. Aquí si es comprensible la falla de las encuestas, y, por lo mismo, merece mayor atención.
¿Por qué ganó Boric si las encuestas decían que iba ganar Jadue? Pues bien, lo más sencillo, la navaja de Ockham, es suponer que las encuestas estaban mal hechas, que es la línea que profundiza Matus. Pero, ¿es solo eso? ¿Es tan simple como que “las encuestas están mal hechas”? Como se señala arriba, las encuestas no existen en el vacío, sino que en un contexto político. Ergo, la pregunta es si el contexto de esa elección influyó en algo en el resultado.
Volvamos a mayo de 2021, a la segunda vuelta de gobernadores. Como describe elegantemente Carlos Correa, el mes del El Olivazo. Pues, fue en ese mes en que el fantasma del comunismo empezó a ascender. Y no se detuvo con la derrota de Karina Oliva (Comunes), sino que siguió aumentando, sobre todo potenciado por el pseudo endoso de Jadue al modelo venezolano, un hecho posiblemente determinante
¿Cuál es el punto? El punto es que hay explicaciones alternativas para explicar la falla de las encuestas que van más allá de la metodología o lo que pasa en el mundo. Enfocarse solo en eso recuerda al adagio del borracho buscando las llaves bajo la luz. Hoy, Chile es un país en movimiento, con votantes fluidos, que se ajustan a candidatos erráticos que, como norma, usan temas coyunturales para apelar a emociones subjetivas que cambian constantemente.
Vamos al punto. Considerando todo esto, creemos que por el contexto político no están las condiciones para hacer un pronóstico. Esto no significa que creemos que las encuestas no serán certeras, ni que modelos de agregación de encuestas no puedan entregar información relevante. Significa que (1) creemos que el sistema político se encuentra en un punto inestable y que (2) se transa demasiada información contradictoria.
Obviamente seguiremos monitoreando el proceso tras bambalinas, con el objetivo de entender por qué se equivocan encuestas, y cómo se puede corregir para prevenir efectos (muchas veces nocivos) sobre el electorado (y la democracia, como bien explica Titelman). Pero estos datos no serán públicos. Lo único público, como ya se anunció por la cuenta de Twitter, serán datos descriptivos que servirán como insumos para informar la ecuación más general.
Antes de ahondar en eso, es importante explicar lo que significa cuando decimos que “el sistema político se encuentra en un punto inestable”. Para no arriesgar ser repetitivos, y perder los pocos lectores que probablemente nos han acompañado hasta aquí, seremos breves. Hay evidencia que creemos que es persuasiva en sugerir que Chile está atravesando un proceso transformativo irreversible.
Ese proceso se desencadenó luego de la reforma electoral de 2015, la cual fijó los incentivos psicológicos del ordenamiento del sistema de partidos. Antes de esa reforma, hubiese sido imposible avizorar la entrada de una tercera fuerza. Después de esa reforma, es claro que el sistema de partidos mutó para siempre. Esa reforma, por cierto, explica algo del ruido de las encuestas en la elección de 2017 (Sánchez, del FA, obtuvo 20% de los votos).
Hoy, con todo lo que ha ocurrido desde el estallido social, y el traspaso de fuerzas en el balance del poder, es imposible pensar que volveremos atrás, al duopolio, como le llamó oportunamente Marco Enríquez-Ominami. La elección de 2021 es la elección de consolidación del sistema de partidos que comenzó a forjarse en 2017. Es altamente probable, en términos lógicos, pensar en una fragmentación decisiva.
En segundo lugar, hay que definir lo que queremos decir cuando decimos que “se transa demasiada información contradictoria”. Pues bien, pensémoslo un momento. Hoy la narrativa en los medios y en las redes sociales es que las encuestas se equivocan. Como mencionamos arriba, esto no necesariamente es el caso. Es parcialmente cierto: no se equivocaron todas ni todas se equivocan para todos los candidatos. Omitir ese detalle no ayuda a la verdad.
Otra idea de información contradictoria: Sichel dice que pasó del 4to lugar al primer lugar en dos por tres. Pero eso no es así. Están los datos. Pero ¿cuál es la verdad que queda en el inconsciente colectivo? Que las encuestas mienten. Lo mismo ocurre cuando se dice que las encuestas se equivocaron para la elección de constituyentes. Una repetición burda que no considera que hubo al menos 28+10 elecciones a medir. No 1 elección a nivel nacional.
Sobre estas dos contradicciones (vitales), hay ruido que cruza tanto el escenario político como el contexto volátil de la opinión pública. Por ejemplo, ¿cómo se entiende el hecho de que José Antonio Kast este liderando las encuestas, siendo que es el único de los representantes que estuvo en el bando del Rechazo (que obtuvo 20%) en el plebiscito de 2020? Es, por decir lo menos contra intuitivo.
Por su puesto, esto se puede explicar desde la perspectiva coyuntural si se consideran los últimos hechos (y cómo han sido enmarcados por los medios): inmigración en el norte, violencia en Santiago y la macrozona sur, además de temas que potencialmente podrían ser vistos negativamente por la ciudadanía, y usadas a favor del candidato, como la acusación constitucional en el Congreso, o las mancha de Rojas Vade en la Constituyente.
¿Cuál es la verdad? ¿Tiene sentido que Kast este liderando o no tiene sentido? Es posible que la derecha este sobre el 40% (sumando a Kast y Sichel) como manifiestan promedios de encuestas, o es una operación política como sugieren los más atrevidos? La verdad es que nadie sabe, y la única respuesta vendrá la noche del 21 de noviembre. Anticiparlo, a esta altura, solo ayuda a introducir más incertidumbre.
Otra contradicción: la baja intención de votos que muestran Provoste y Sichel. Obvio, tiene sentido si se lee el diario de cada día. Pero la verdad es que también es contra intuitivo cuando se mira en lo más amplio del escenario político. Ambos son apoyados (“apoyado” en el caso de Sichel) por sendas coaliciones políticas que tienen candidatos legislativos fuertes en todo Chile. ¿Por qué se descarta a priori un coattail effect?
Considerando lo anterior, es posible pensar en un escenario favorable tanto para Provoste como para Sichel (más para la primera que para el segundo por razones obvias). Pero, al mismo tiempo, en un escenario de polarización política, cobra sentido que los candidatos más populares sean precisamente los que más explotan el eje del caos-orden, pues son ellos quienes más pueden apelar a las emociones de los votantes. Es el caso de Boric y Kast.
Un ejemplo final. ¿Cómo se explica la persistencia de Parisi en las encuestas? El candidato ha marcado ininterrumpidamente desde 2018 en preguntas abiertas y cerradas, sin poner un pie en el país. De hecho, nadie sabe quién lo apoya ni por qué, y aun así figura consistentemente. ¿Estamos en condiciones de decir que no hay que creer en las encuestas y que tiene más sentido pensar que no va a marcar por que no está presente? Dudamos.
En fin, no están las condiciones para creer ni desconfiar de las encuestas. Uno puede desconfiar en el método, pero si las encuestas le apuntan a la elección, cuál es la utilidad del argumento. ¿La calidad de una encuesta se debe medir por su capacidad predictiva o por su metodología? Son dos caras de la misma moneda que se debaten constantemente en la academia. Aprovechamos de dejar una lista de literatura aquí para quienes quieran conocer más de aquello.
Es posible que las encuestas le apunten a la elección y es posible que no le apunten. El problema es que no sabemos cuál es la probabilidad de cada una de esas opciones, y, nos parece que jugar a experimentar en un momento político tan inestable como el actual no ayuda a nadie. Es por eso que temprano en el ciclo decidimos no hacer un pronóstico. Decidimos tratar de aportar de otra manera, respetando los peligros del contexto político.
El punto es que creemos que en un ciclo como el actual, donde estamos parados en la esquina de la inestabilidad política con la información contradictoria, lo mejor que podemos hacer es transparentar todo en la medida de lo posible. Es decir, funcionar como un repositorio público de datos para que cada cual pueda usarlos para hacer su propio análisis. La idea es fomentar la transparencia política y electoral.
Si ya no es claro, estamos diciendo que no sabemos si las encuestas le pueden apuntar o no. A esta altura, no sabemos si la mejor encuesta del mundo podría apuntarle. Por lo mismo, sugerimos mirar toda la información posible y no solo las encuestas. De hecho, en nuestro sitio web ponemos a disposición muchos datos más allá de las encuestas para entender cómo se mueve el balance de poder entre los distintos candidatos.
Por ejemplo, entre otras cosas, sugerimos mirar endosos electorales (apoyo de las principales autoridades a los candidatos), patrones en la búsqueda de candidatos en Google, y tendencias en el financiamiento electoral por pactos y candidatos. Estas son variables que son parcialmente independientes (en principio) del desempeño de los candidatos en las encuestas. Por lo bajo, sirven como una especie de robustness check.
El gráfico que muestra la evolución de las encuestas en nuestra web no es un pronóstico, es solo una recopilación de todas las encuestas que se han publicado acompañados por simples promedios de 30, 15 y 7 días. Es una información agnóstica, que sirve tanto para criticar a las encuestas como para apoyarlas. Pero advertimos, de forma tajante, que todo puede cambiar de un momento a otro. Incluso si alguien les cree a las encuestas, hay un riesgo contextual.
Por ejemplo, si la elección hubiese sido hoy, y le creyéramos a las encuestas, estaríamos pensando que los ganadores serían Boric y Sichel (pues fue eso lo que decían hace 15 días, antes de la hipotética veda). Pero, en el intertanto, sabemos que las cosas han cambiado dramáticamente. Es decir, si nos hubiéramos quedado 15 días atrás, tendríamos una impresión absolutamente diferente de la foto más actualizada que podríamos tener.
Por último, la lista de encuestas los promedios, y las tendencias servirán como una base para determinar (1) si las encuestas se equivocaron, y (2) por cuánto se equivocaron. Además de la lista completa, descargable en formato Excel, tenemos el repositorio completo de encuesta publicada en PDF, por si nuestros lectores los requieren. No ignoramos ninguna encuesta, ni modificamos (transformamos) sus datos. Lo que usted ve online, es lo que ellos publicaron.
En fin, llamamos a los lectores a ejercer una duda razonable: observar la información, toda la información, y luego decidir. El rol de las encuestas en la política no es un tema de blancos y negros, y menos unidimensional. En este breve artículo hemos intentado dar un poco más de contexto para que el debate se desarrolle de forma informada. Sabemos que información parcial conduce a conclusiones parciales. Y es eso lo que buscamos prevenir.
![]()